

システムズのマイグレーションコラム

Vol.22 Oracle DBのレプリケーション移行 (その2)
2020.03.27
AWSで実践!RDSへのDBマイグレーション(Oracle to Oracle編)
Oracle Data Pump を使用したデータ移行
Oracle DBには、エクスポートおよびインポート・ユーティリティとして Oracle Data Pumpが提供されています。
これらのエクスポート(expdp)および、インポート(impdp)ユーティリティによって Oracle DBのアップグレードが容易に実現できます。
本項では、Data Pump(expdp/impdp)を使用したデータ移行手順について紹介していきます。
目次
Data Pumpで移行する
全体の流れとしては、 移行元からデータをエクスポートしてS3にアップロードし、
移行先でダウンロードしてインポートします。
手元に既にDumpファイルがある場合は、
「移行元からエクスポート」と「S3へDumpファイルをアップロード」の手順を飛ばして、
AWSのマネジメントコンソールから、Dumpファイルを直接S3へアップロードして下さい。
それでは、順番にやっていきます。
RDSのS3統合機能を有効化
S3連携は、RDSコンソールのオプショングループで設定を行います。
「グループの作成」から、オプショングループを新規で作成します。
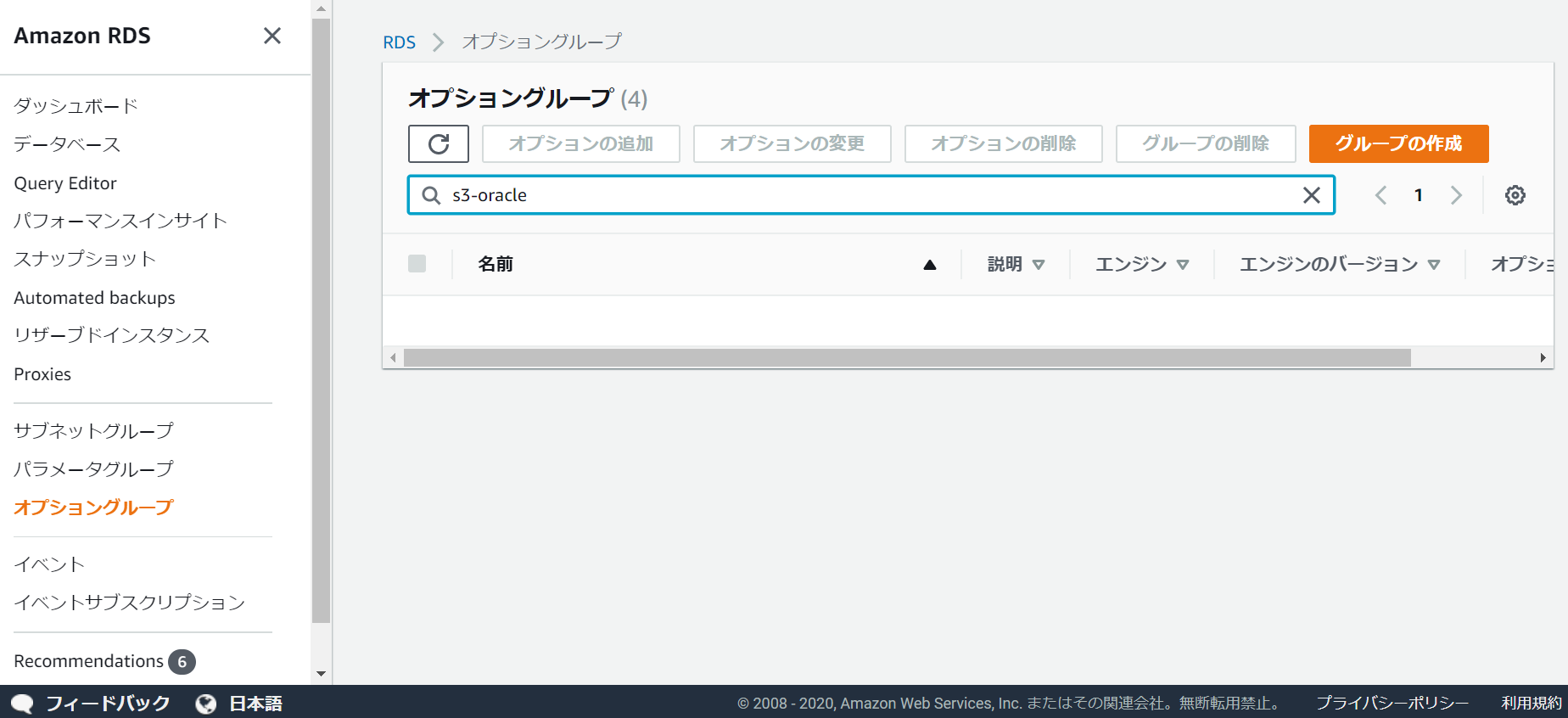
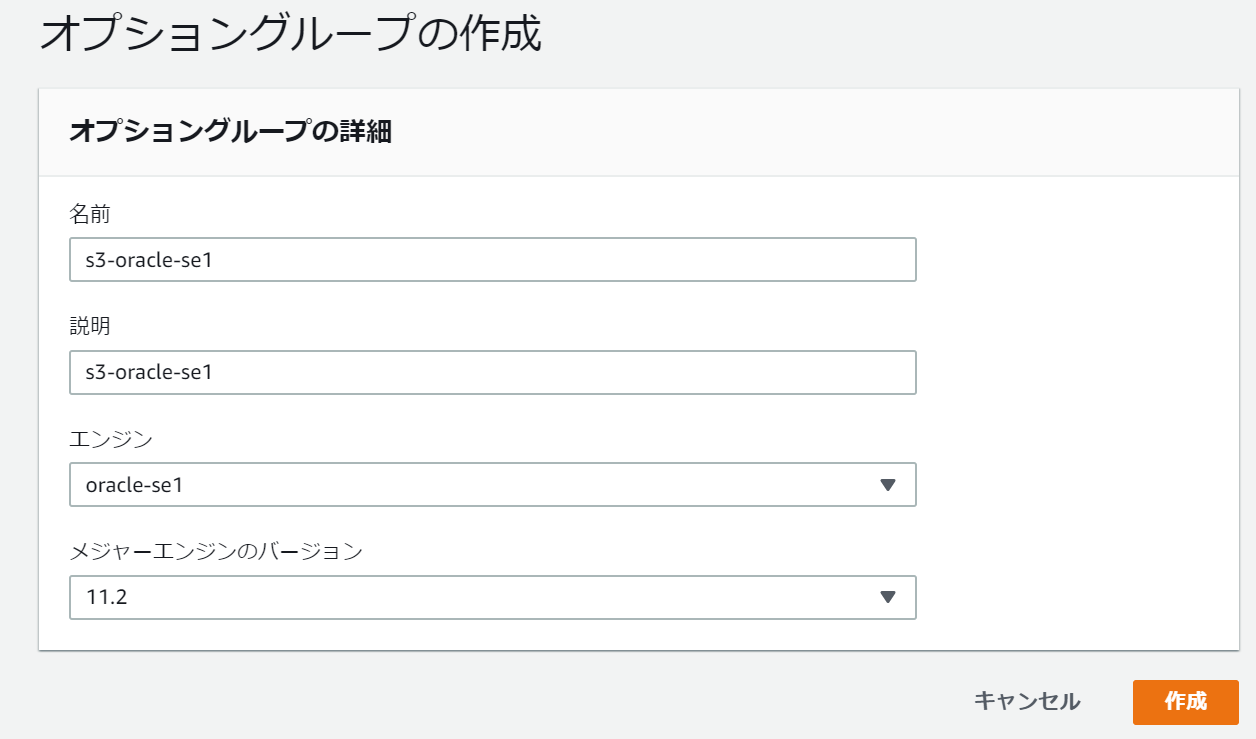
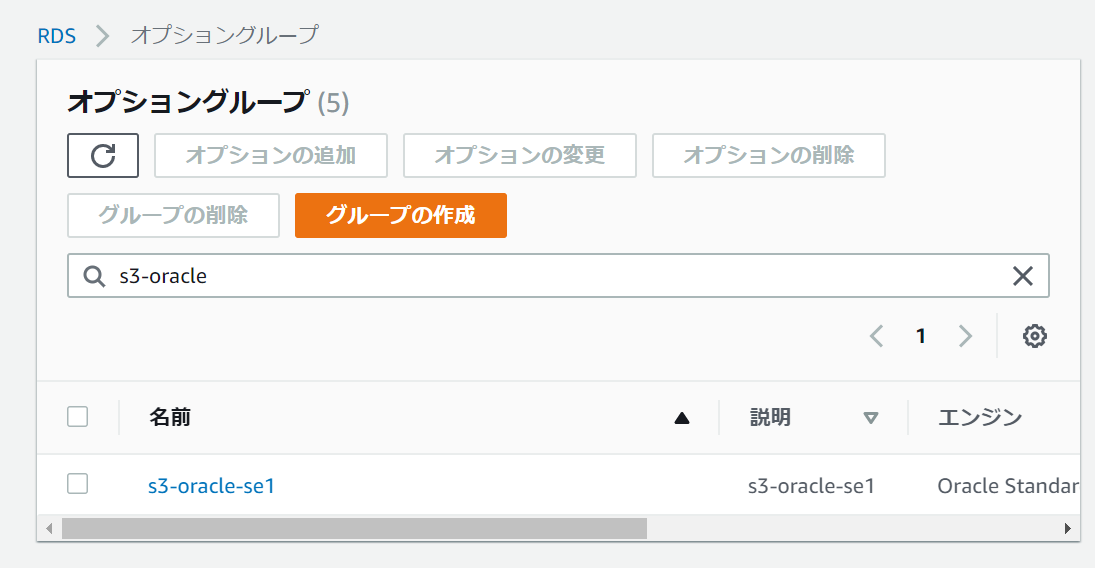
今回は、移行元と移行先で異なるライセンスを使用しているため、
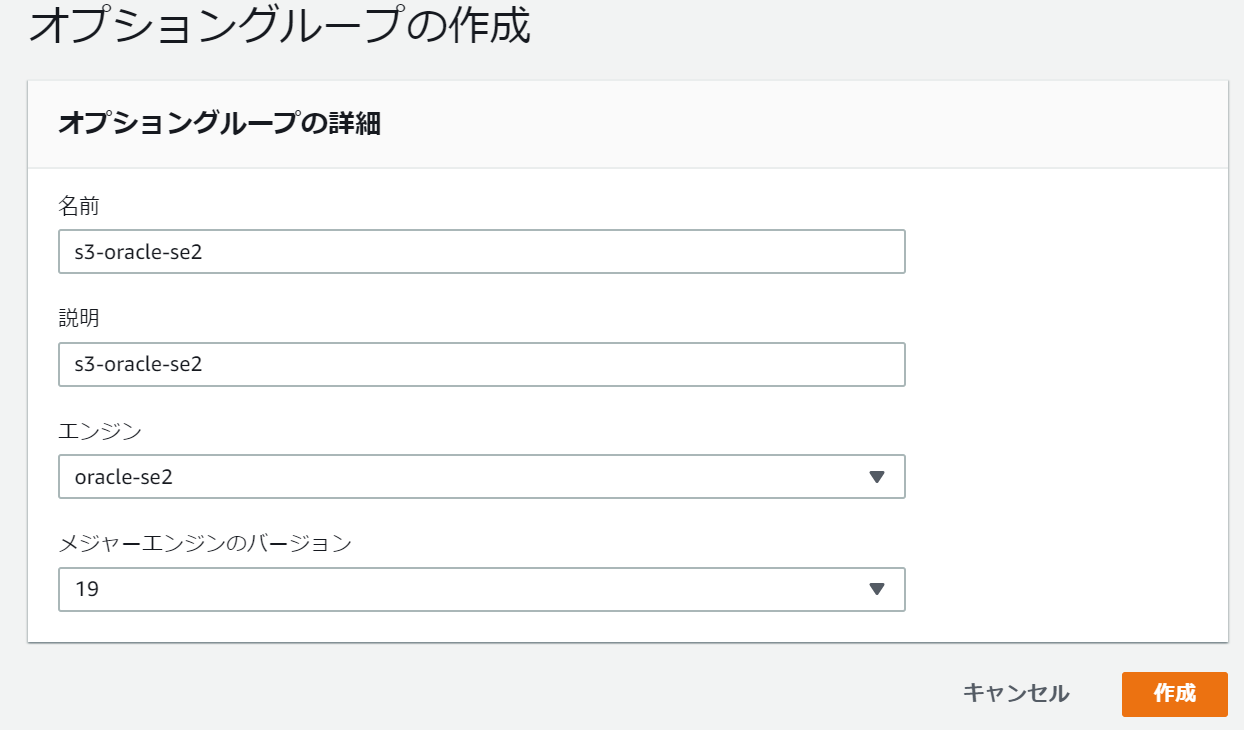
se2用のオプショングループも新規作成します。
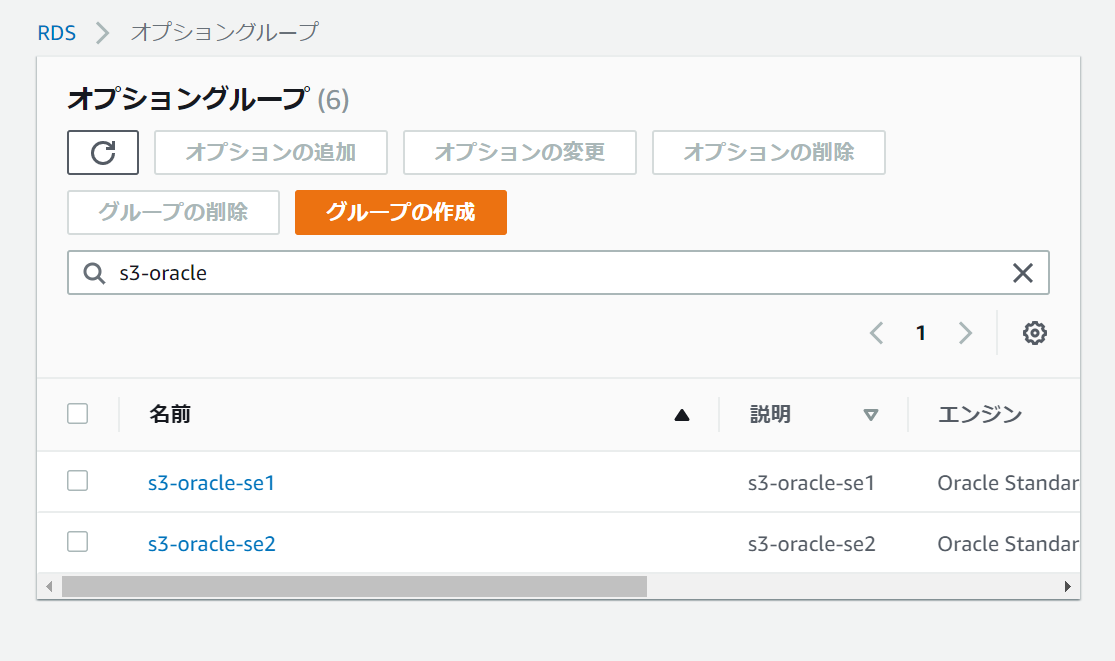
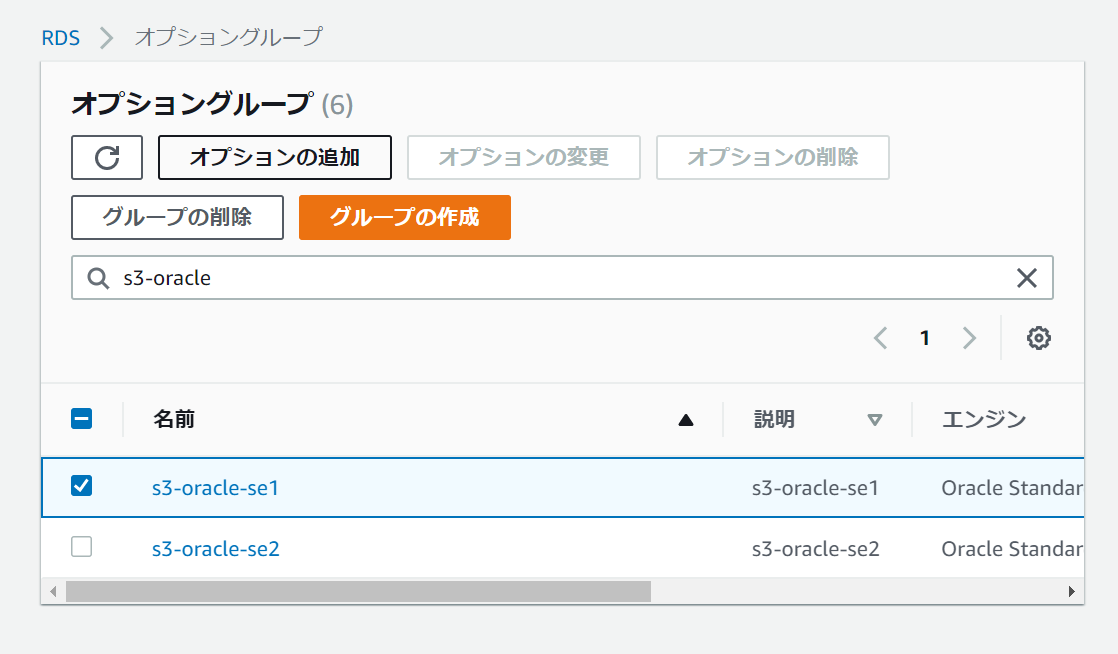
作成したグループを1つ選択して、
「オプションの追加」を行います。
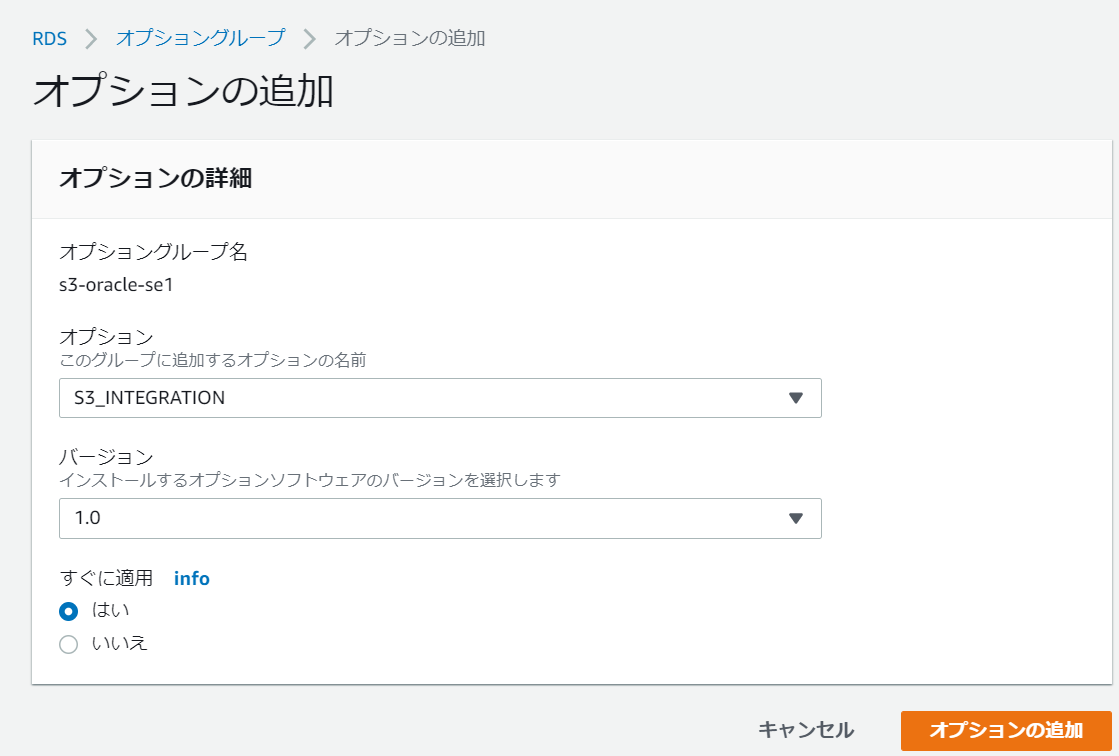
S3_INTEGRATIONを選択し、バージョン 1.0で「すぐに適用」を選んで、
オプションの追加を押します。
se2のオプショングループも同様に設定します。
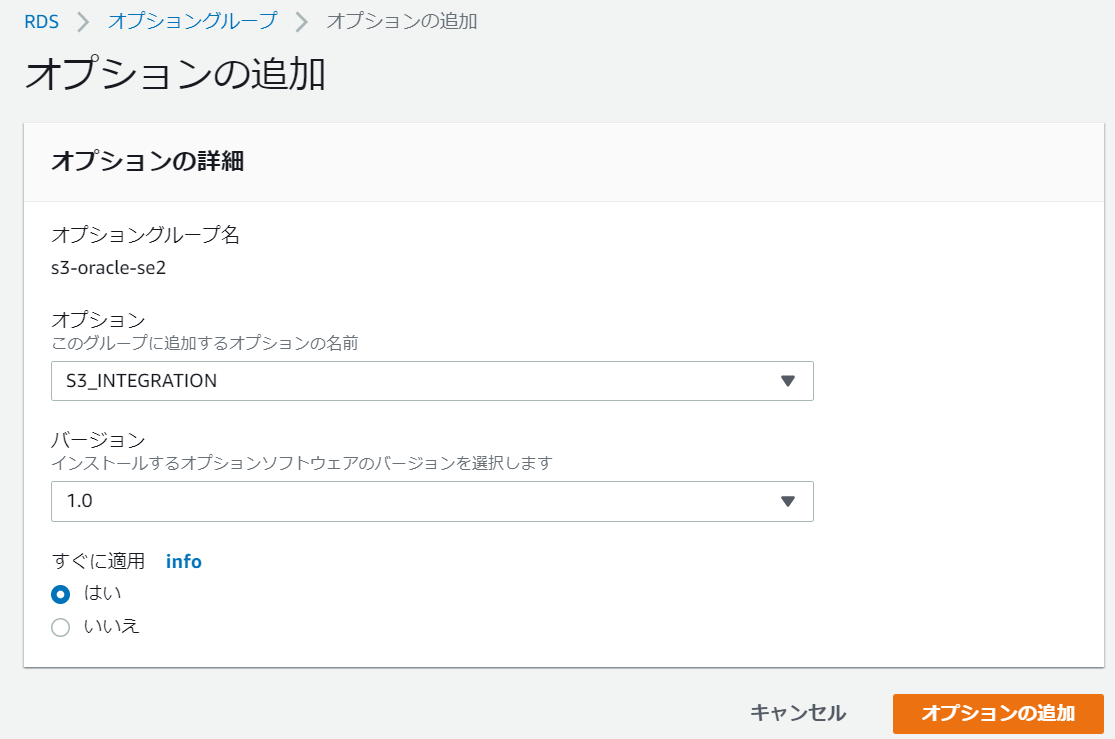
次は、設定したオプショングループを、RDSインスタンスに適用します。
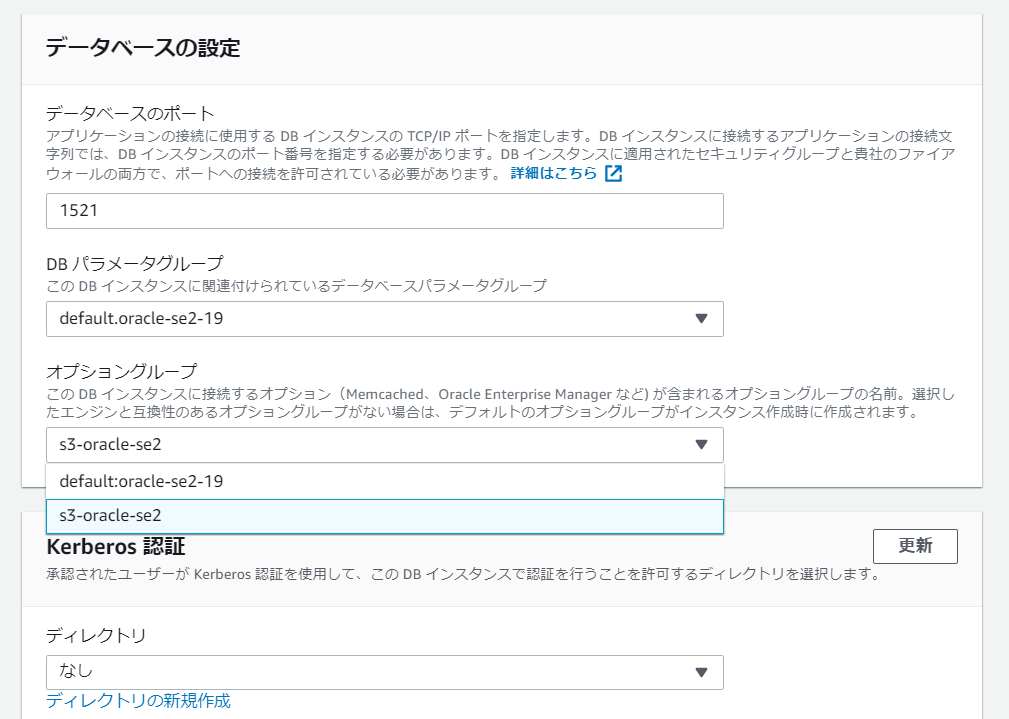
RDSコンソールのデータベースから、インスタンスを選択して「変更」を押します。
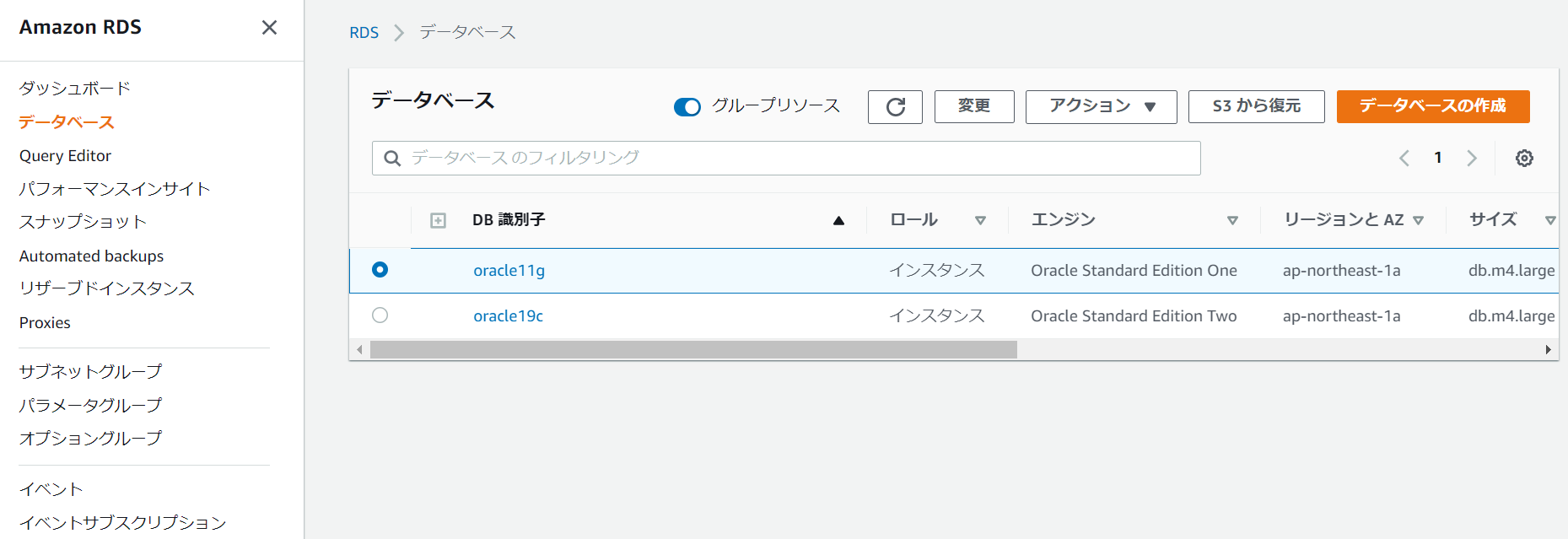
データベースの設定内に、オプショングループの項目があるので、
上記で作成したオプショングループを選択します。
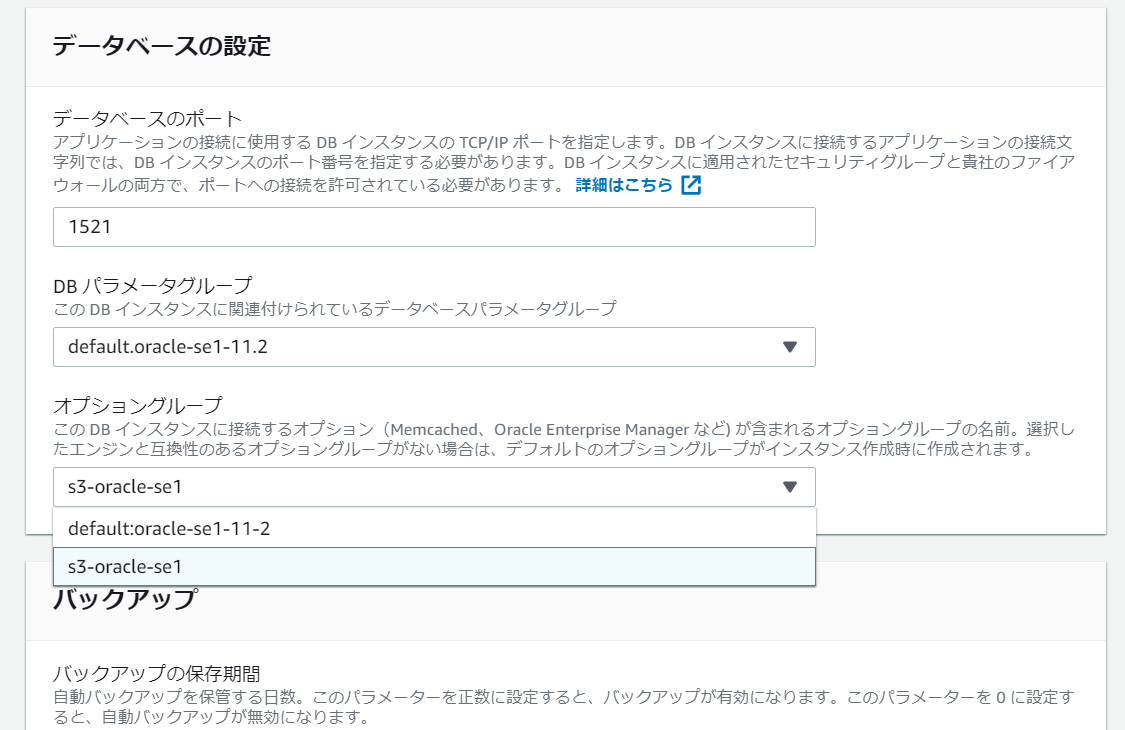
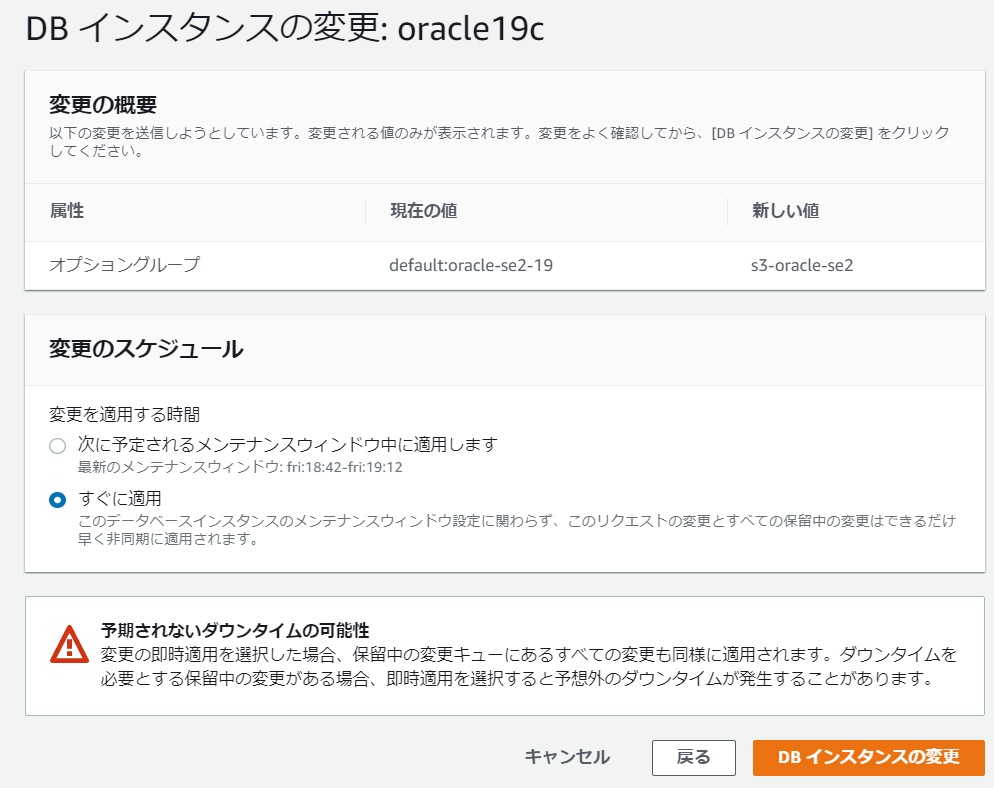
次の画面へ進み、変更を適用します。
今回は検証のため変更のスケジュールで「すぐに適用」を選んでいますが、
DBのダウンタイムが発生するため、適用の際は注意して下さい。
もう片方のインスタンスも、同様に適用します。
しばらく時間が経つと、変更が適用されます。
S3の準備
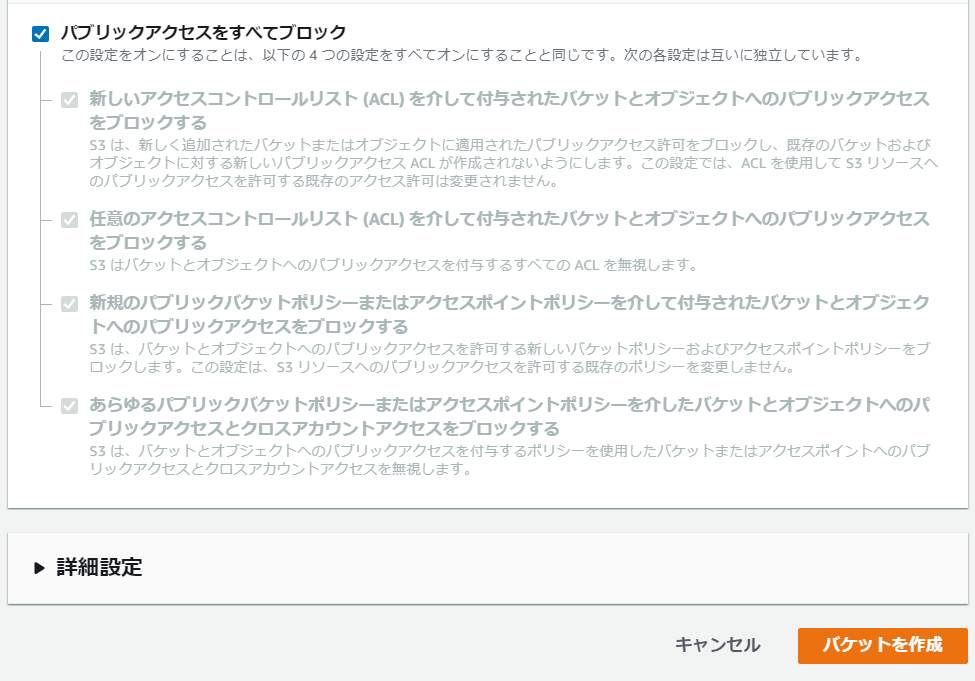
Dumpファイルを格納するために、S3バケットの作成を行います。
S3バケット名はグローバルに一意な名前を付ける必要があるため、
画像の通りの名前ではなく、適宜変更して作成して下さい。
今回は、同一AWSアカウント内で利用するだけなので、
アクセス制御はデフォルトの「パブリックアクセスはすべてブロック」のままにしておきます。
IAMの設定
次は、RDSがS3にアクセスできるように、IAMの設定を行います。
IAMの画面から、ポリシーを選択して「ポリシーの作成」を押します。
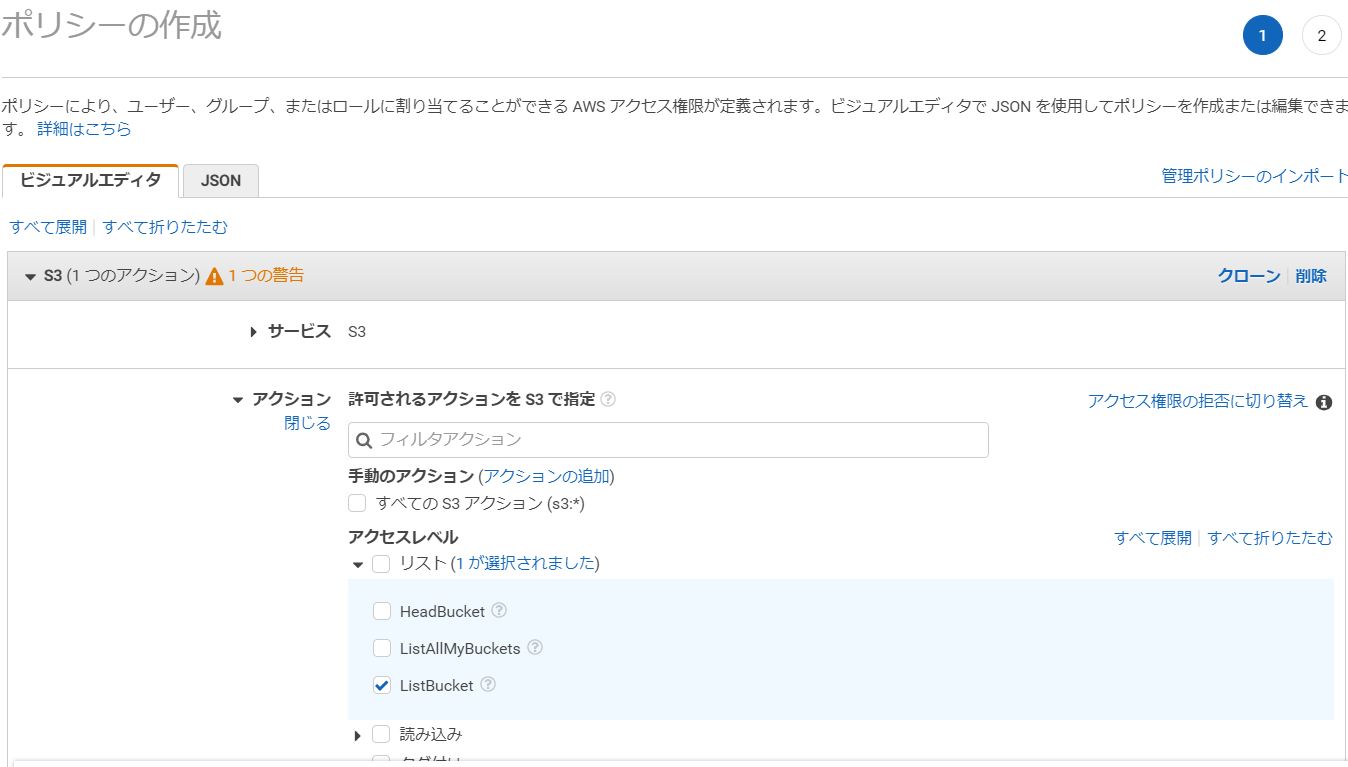
サービスは「S3」を選択します。
アクセスレベルリストの項目を展開し、「ListBucket」をチェックします。
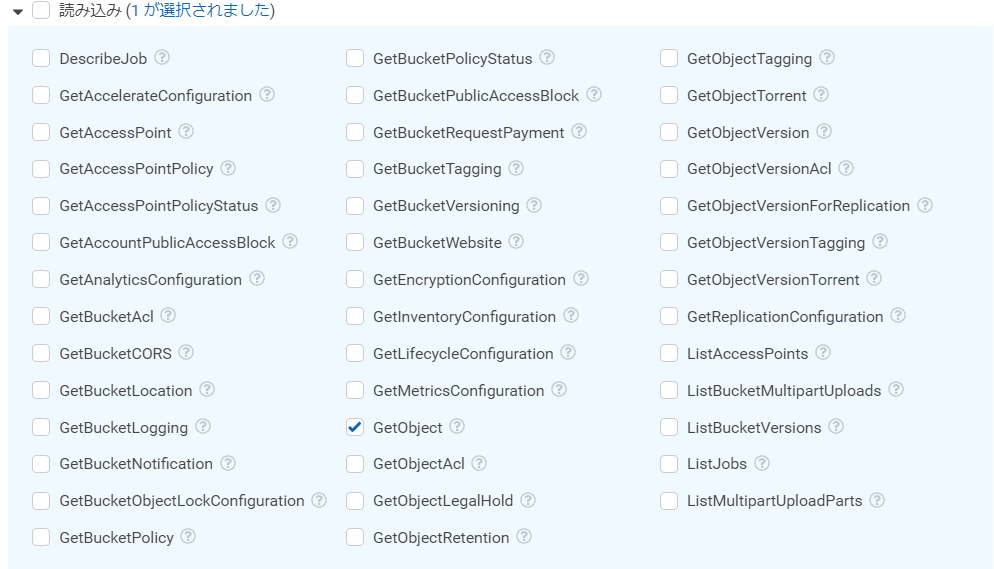
読み込みのリストは、「GetObject」を選択します。
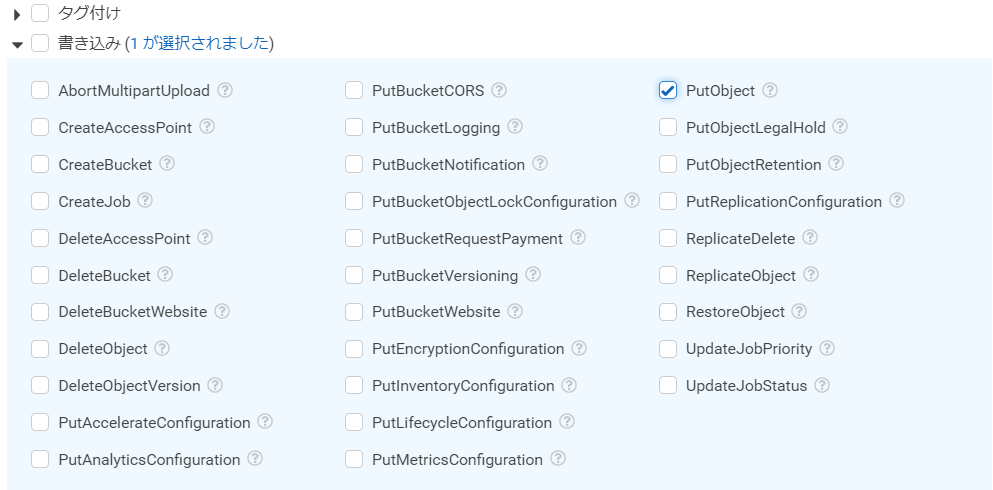
書き込みのリストは、「PutObject」を選択します。
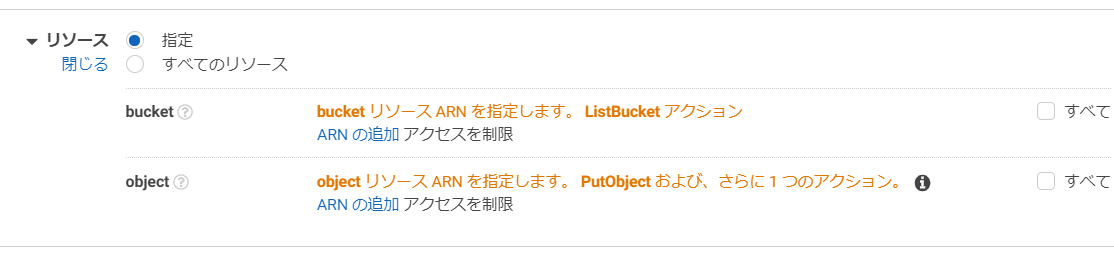
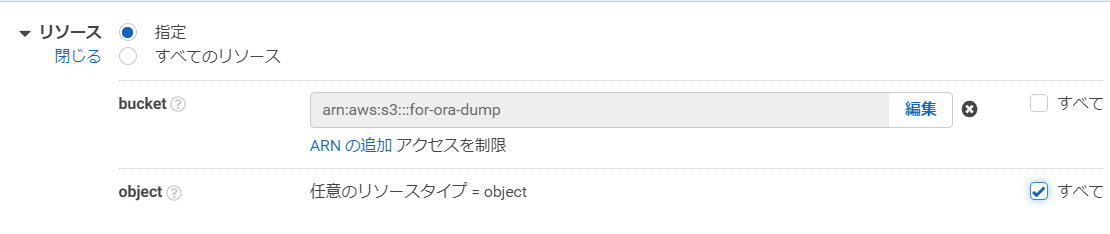
リソースは、bucketの欄は「指定」を選択して、「ARNの追加」を押します。
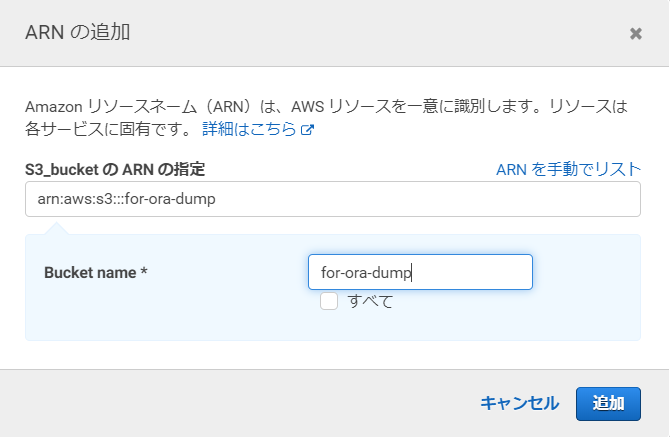
先ほど作成したS3バケット名を入力して、「追加」を押します。
objectの欄は「すべて」を選択します。
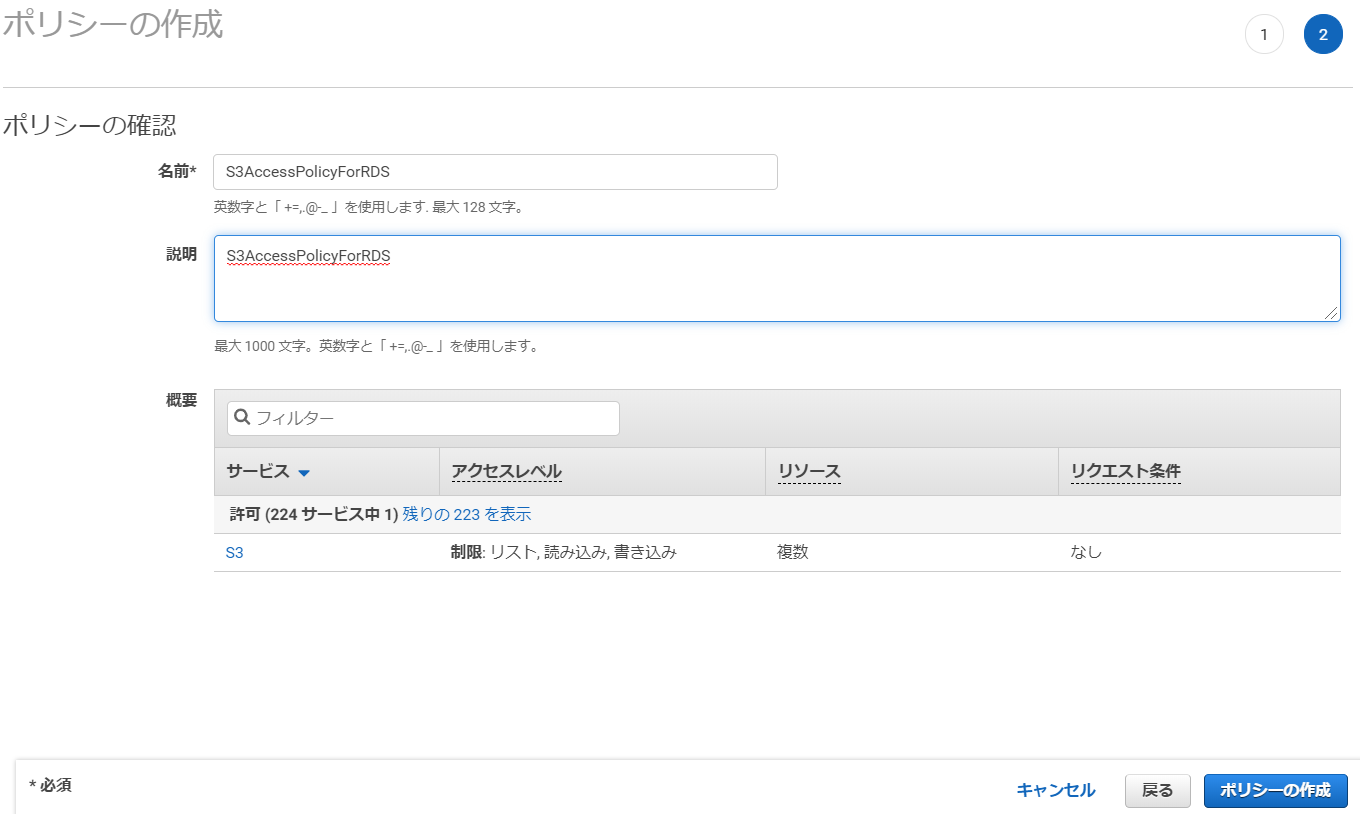
「ポリシーの確認」を押して、次の画面に進みます。
ポリシー名と説明を入力して、「ポリシーの作成」を押します。
次に、作成したポリシーをロールに紐づけます。
IAMの「ロール」項目から、「ロールの作成」を押します。
「AWSサービス」の中から、サービス一覧で「RDS」を選択します。
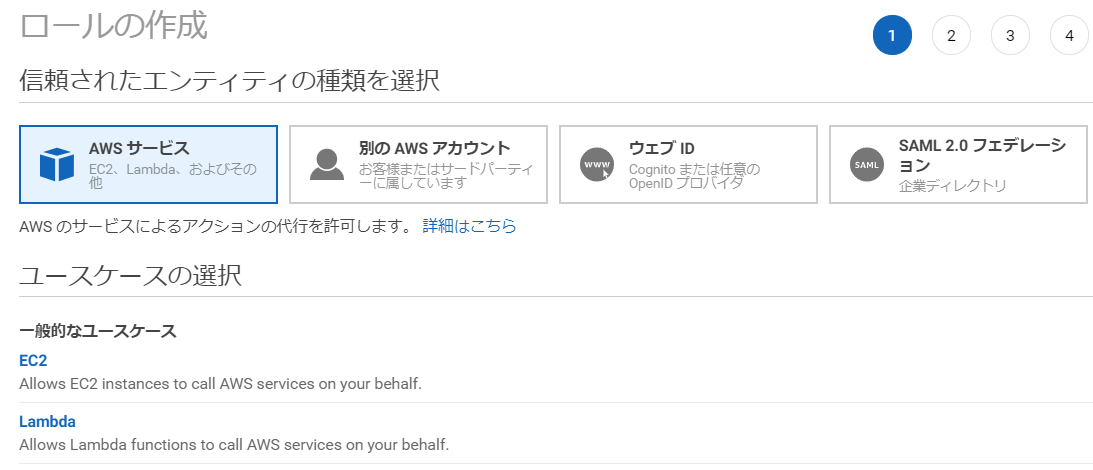
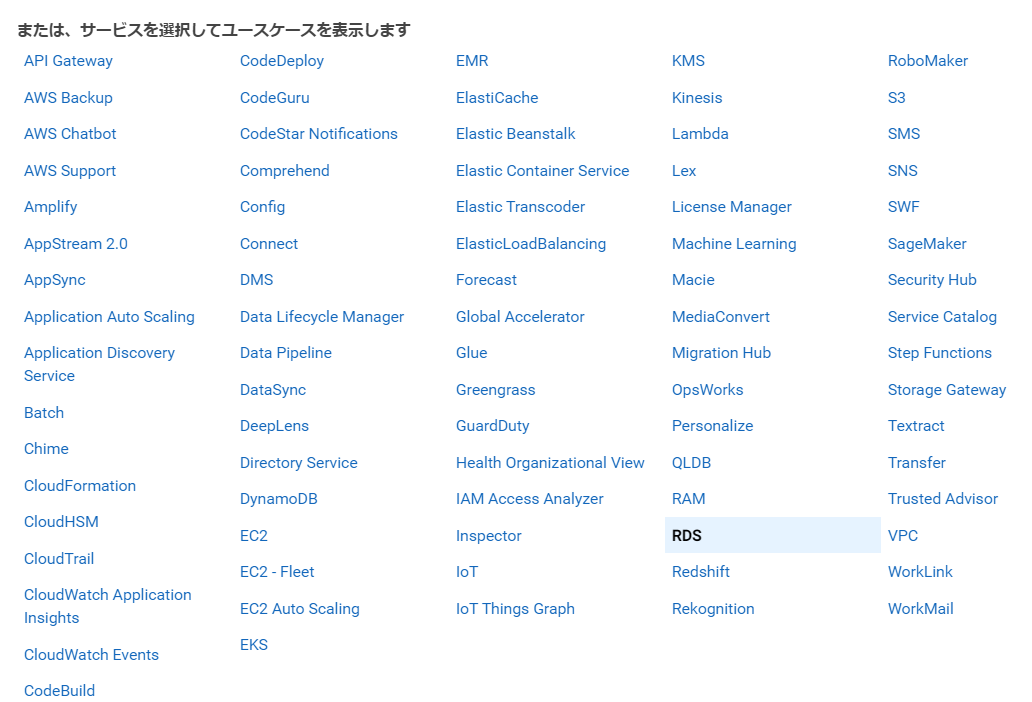
ユースケースの選択からは、「RDS – Add Role to Database」を選択して、
次の画面に進みます。
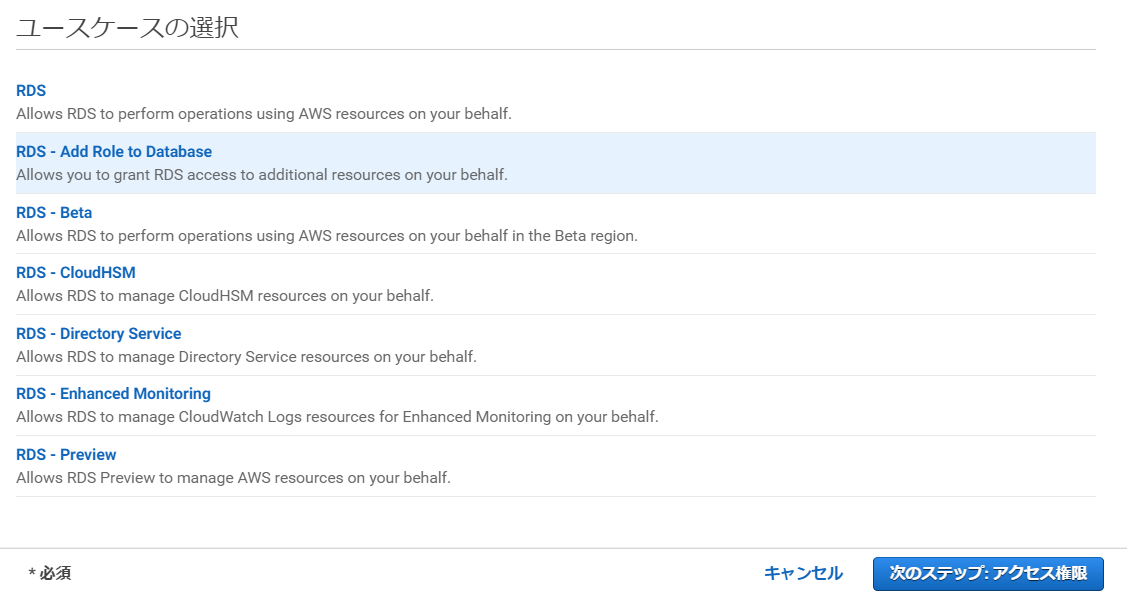
ポリシーのフィルタで、先ほど作成したポリシーを選択し
必要に応じて、タグを追加して次の画面へ進みます。
(不要な場合はタグ入力無しでも問題ありません。)
ロール名と説明を入力して、「ロールの作成」を押します。
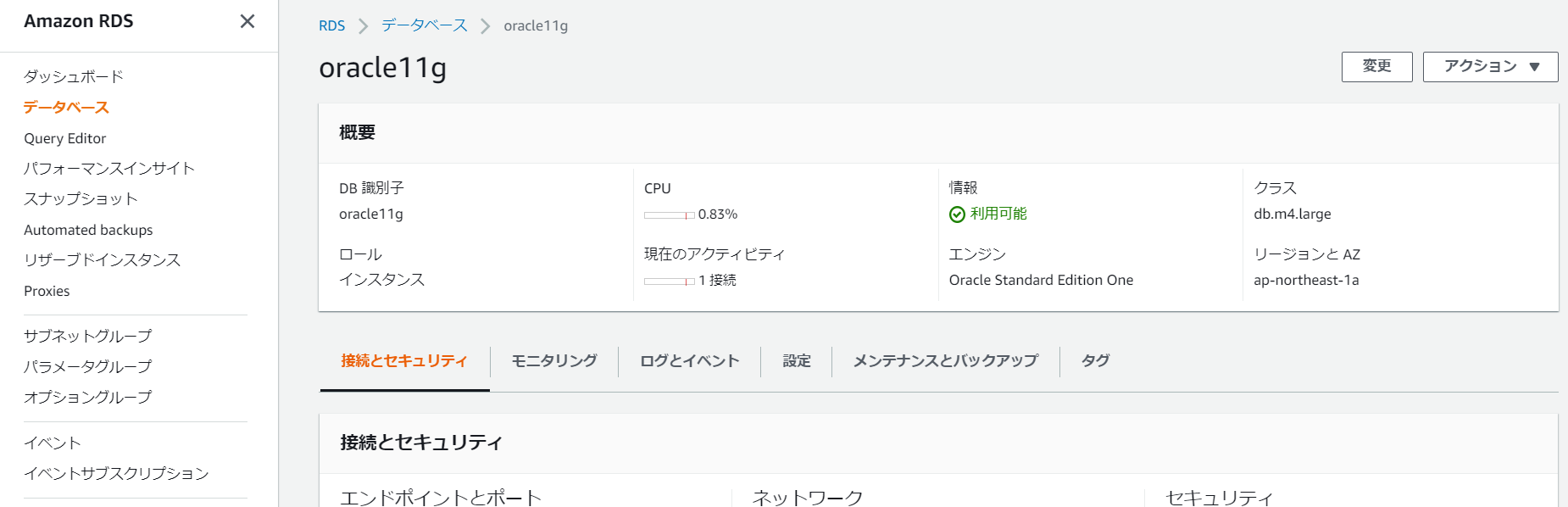
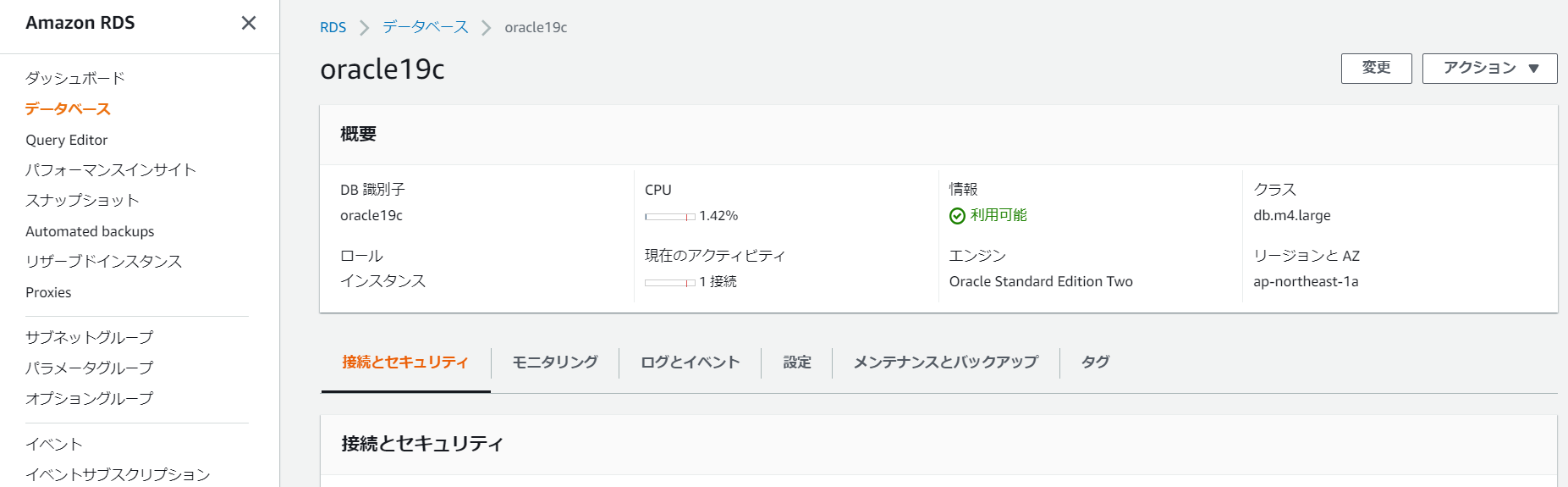
まずは移行元RDSインスタンスに、作成したIAMロールを設定していきます。
IAMロールの管理 項目から、ロールを選択して「ロールの追加」を押します。
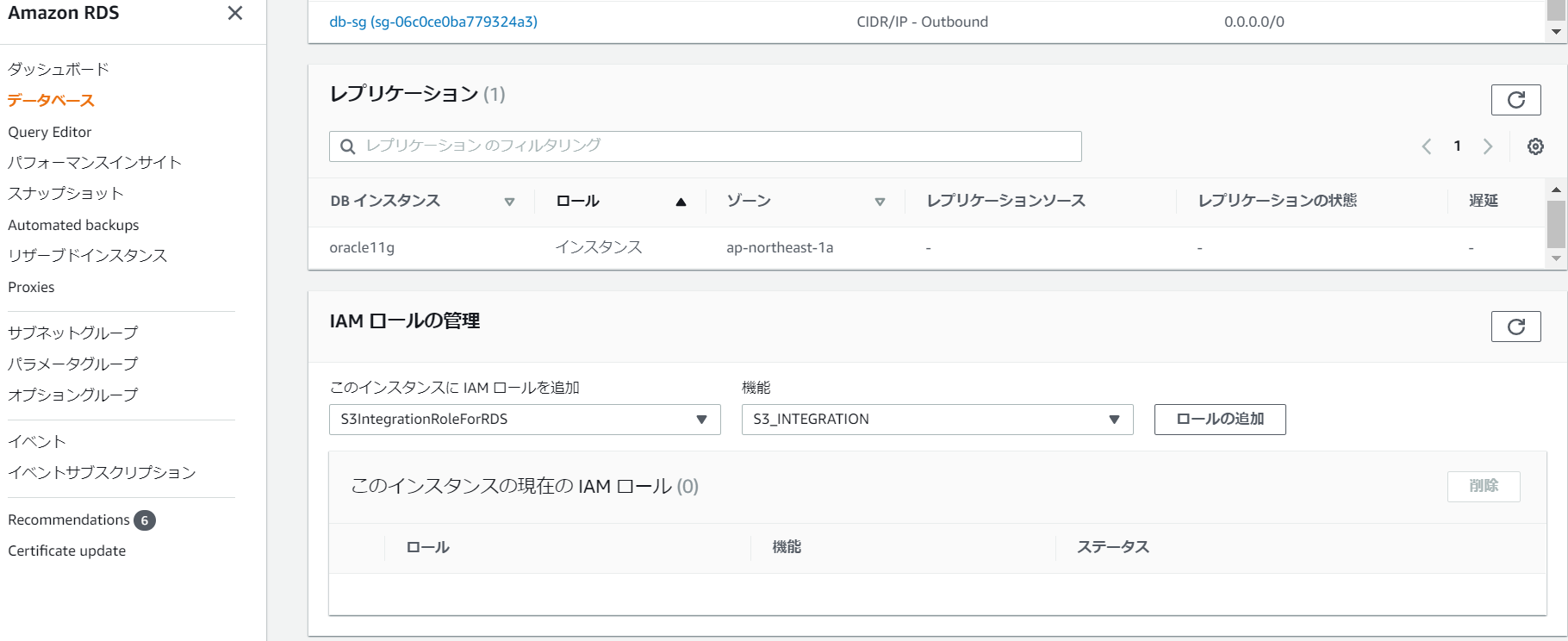
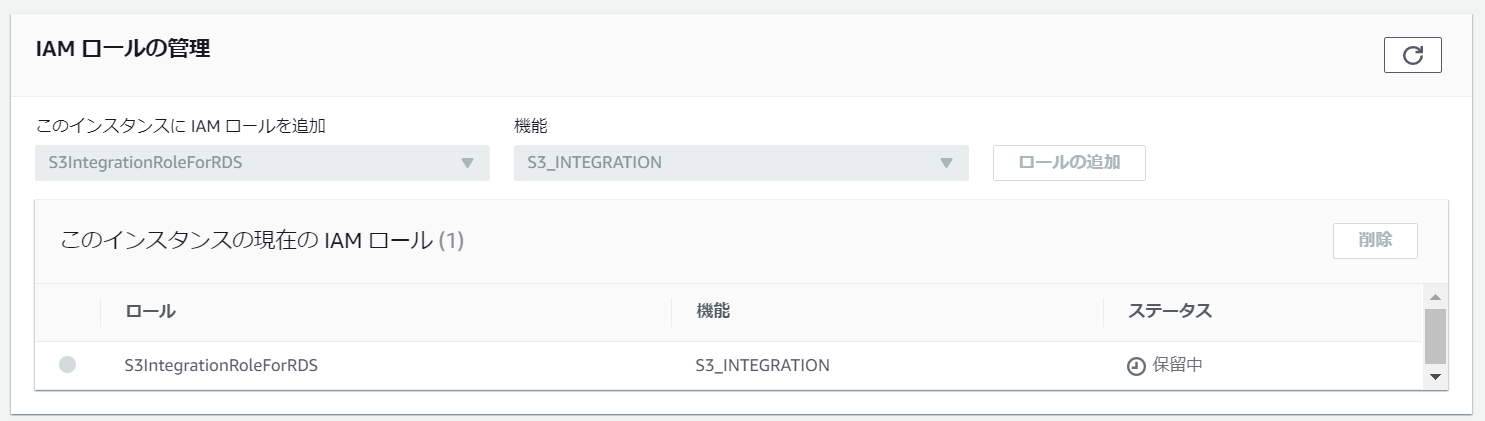
移行先DBにも同様にロールを追加します。
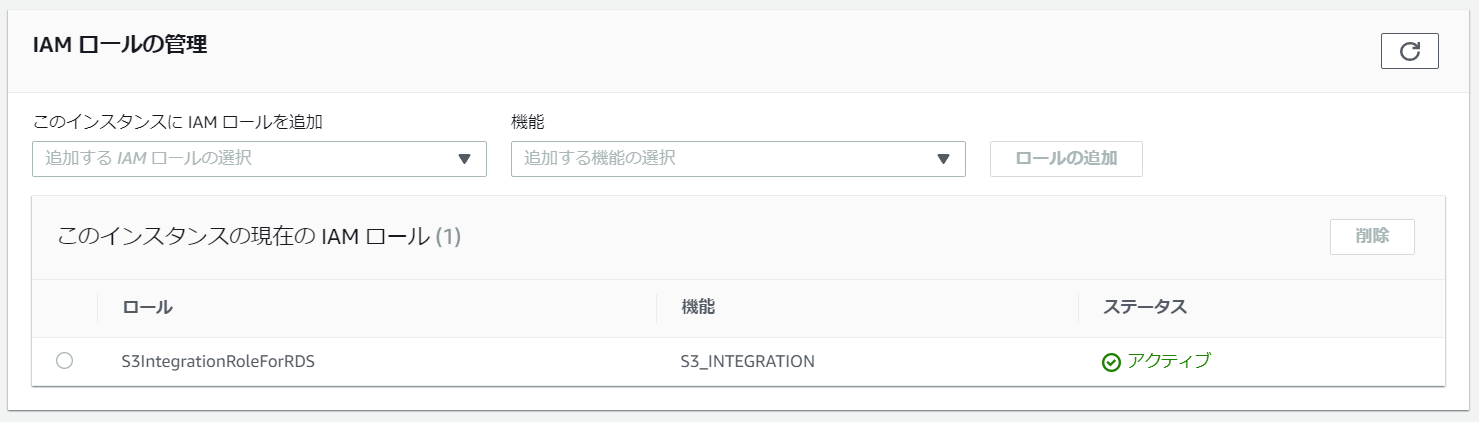
少し時間が経つと、ステータスが「アクティブ」に変わります。
これで、RDSからS3へのアクセスが出来るようになりました。
移行元からエクスポート
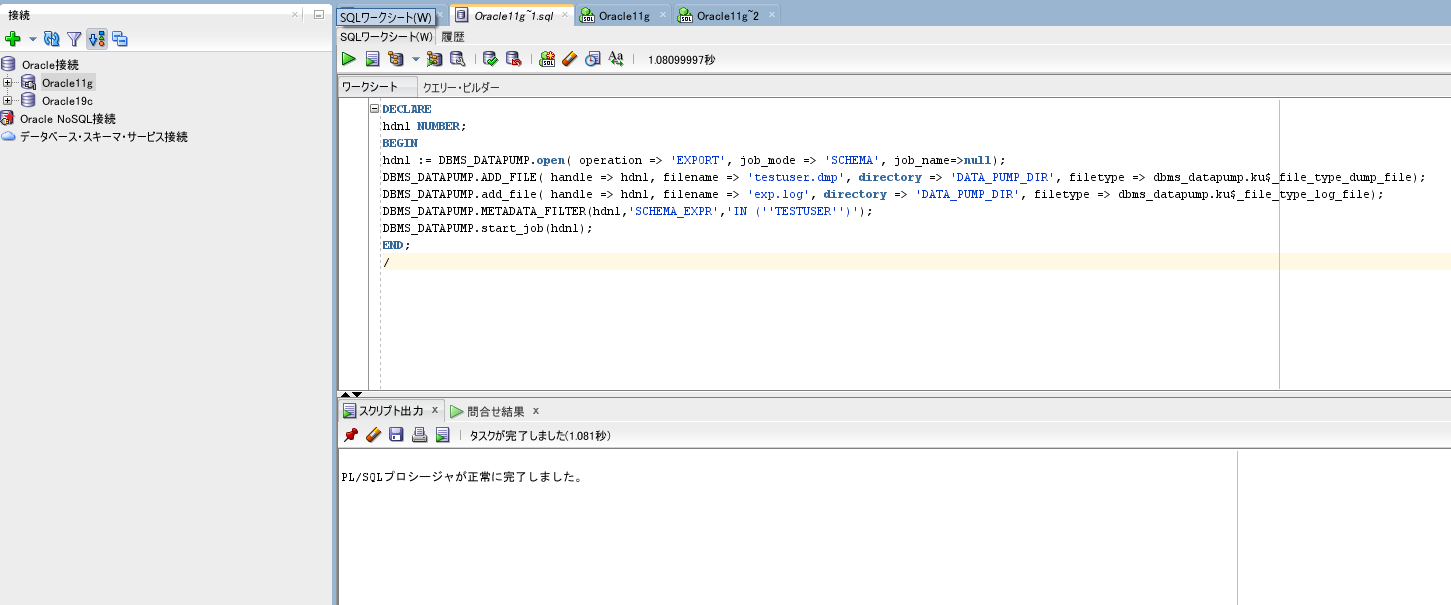
移行元DBから、DBMS_DATAPUMPパッケージを使用して、
Dumpファイルを作成します。
以下のパラメータは適宜書き換えて下さい。
handle => hdnl, filename => ‘Dumpファイル名’
handle => hdnl, filename => ‘ログファイル名’
(hdnl,’SCHEMA_EXPR’,’IN (”スキーマ名”)’)
DECLARE
hdnl NUMBER;
BEGIN
hdnl := DBMS_DATAPUMP.open( operation => 'EXPORT', job_mode => 'SCHEMA', job_name=>null);
DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'testuser.dmp', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file);
DBMS_DATAPUMP.add_file( handle => hdnl, filename => 'exp.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file);
DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''TESTUSER'')');
DBMS_DATAPUMP.start_job(hdnl);
END;
/ 移行元DBに接続し、上記のPL/SQLを実行します。
スキーマ名や、Dumpファイル名、ログファイル名は適宜変更して下さい。
(今回はSQL Developerで接続していますが、任意のクライアントツールで大丈夫です。)
ダンプファイルは、DATA_PUMP_DIRというディレクトリ配下に格納されているため、
SQLを発行してファイルを確認できます。
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR'));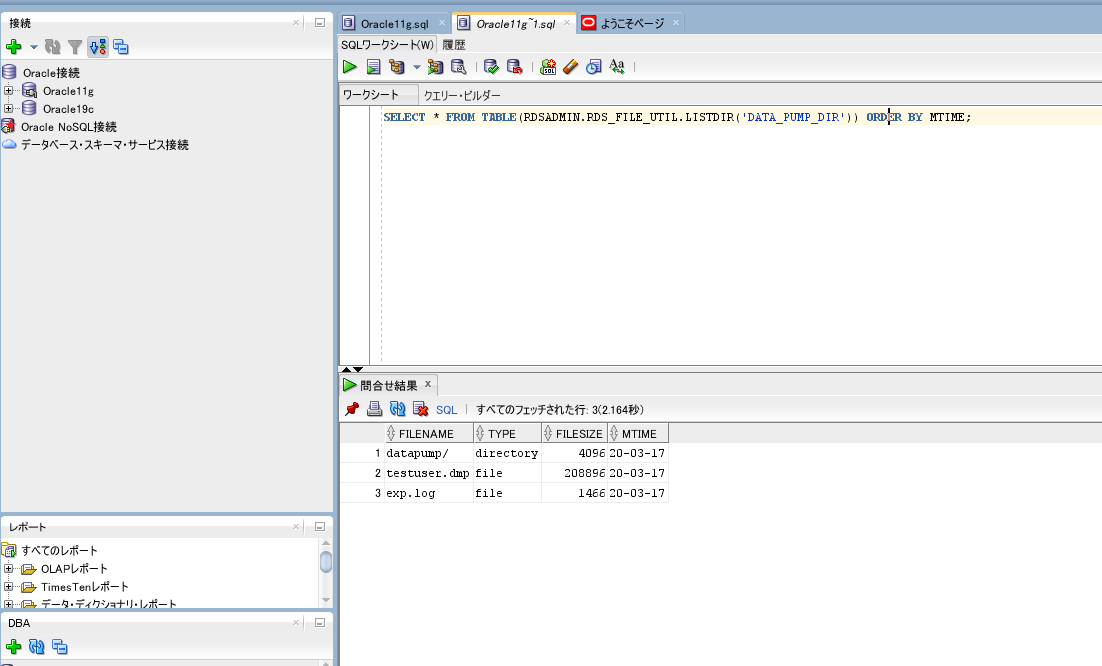
格納されたファイルの中身を参照する場合は、
以下のSQLを発行して確認します。
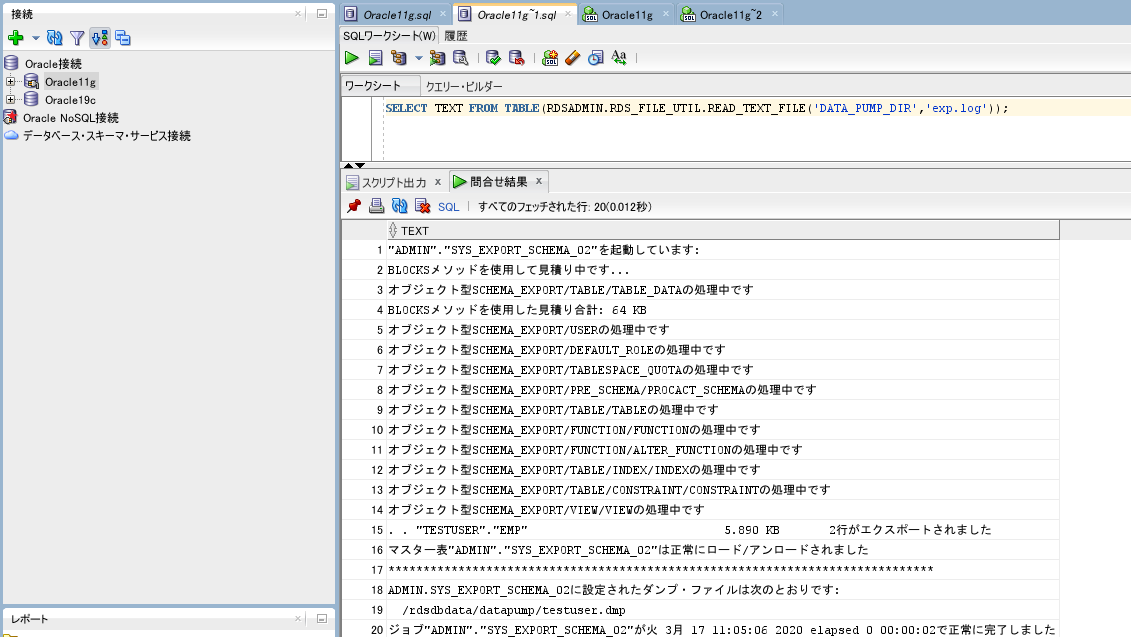
これで移行元のDumpファイルが用意出来ました。
S3へDumpファイルをアップロード
次は作成したDumpファイルを、
以下のSQLを発行する事で、S3へアップロード出来ます。
公式ドキュメント:Amazon S3 の統合
以下のパラメータは適宜書き換えて下さい。
p_bucket_name => ‘S3バケット名’
p_prefix => ‘アップロードするファイル名のプレフィックス’
SELECT
rdsadmin.rdsadmin_s3_tasks.upload_to_s3(
p_bucket_name => 'for-ora-dump'
, p_prefix => 'testuser.dmp'
, p_s3_prefix => ''
, p_directory_name => 'DATA_PUMP_DIR'
) AS TASK_ID
FROM
DUAL;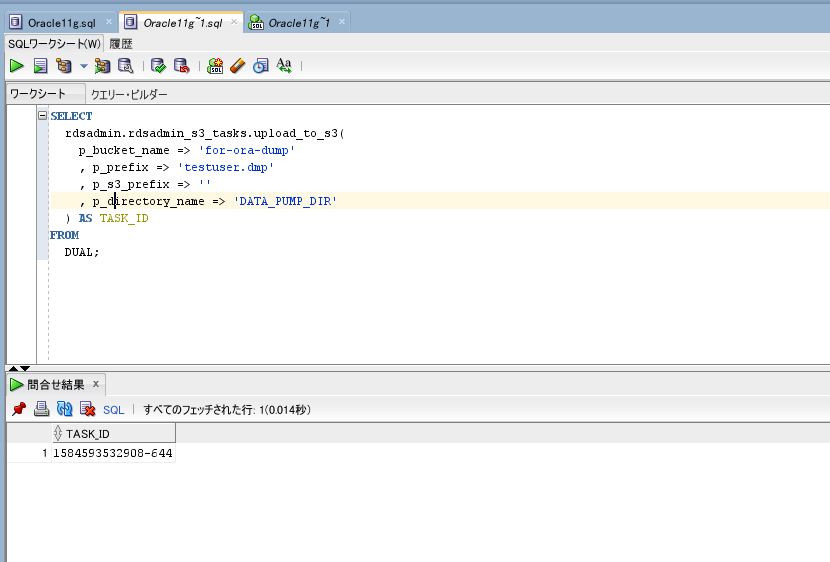
返却されたTASK_IDの名前を含むログが生成されるので、
参照する事でアップロード状況を確認できます。
※ダンプファイルが大きいと、アップロードに時間を要する場合があります。
SELECT
text
FROM
TABLE (
rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-1584593532908-644.log')
);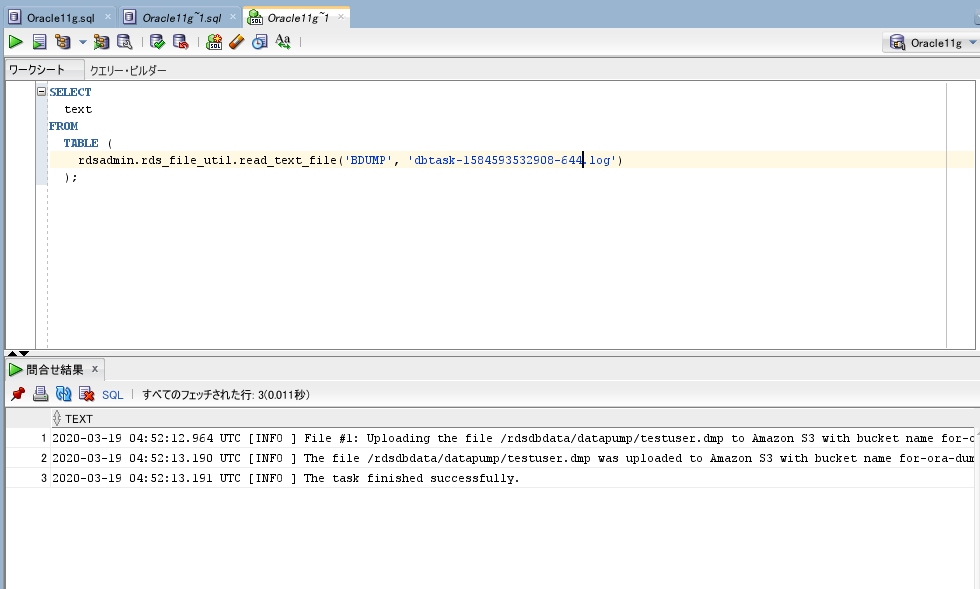
「The task finished successfully.」と表示されているため、
成功しています。
AWSコンソールで、S3側でも確認してみます。
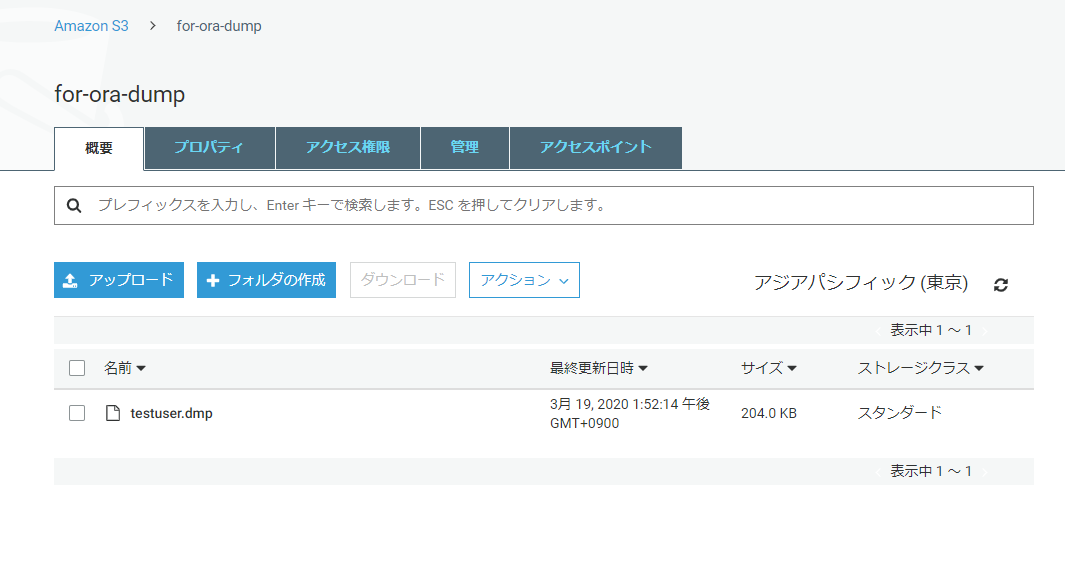
Dumpファイルがアップロードされています。
S3からDumpファイルをダウンロード
アップロードしたDumpファイルを、移行先DBへダウンロードしてきます。
移行先DBへ接続し、以下のSQLで、S3からダウンロード出来ます。
※移行元で誤って発行してしまわないようにご注意下さい。
以下のパラメータは適宜書き換えて下さい。
p_bucket_name => ‘S3バケット名’
SELECT
rdsadmin.rdsadmin_s3_tasks.download_from_s3(
p_bucket_name => 'for-ora-dump'
, p_directory_name => 'DATA_PUMP_DIR'
) AS TASK_ID
FROM
DUAL;アップロードの時と同様で、TASK_IDが返却されます。
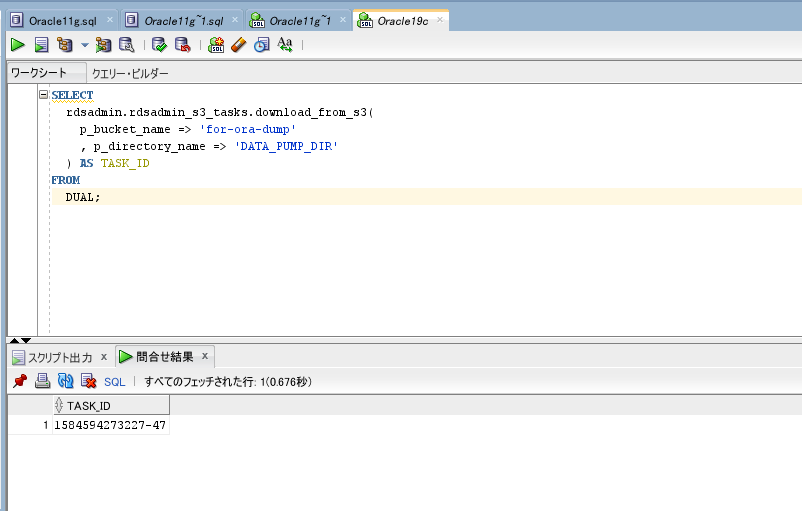
ログを確認してみます。
SELECT
text
FROM
TABLE (
rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-1584594273227-47.log')
);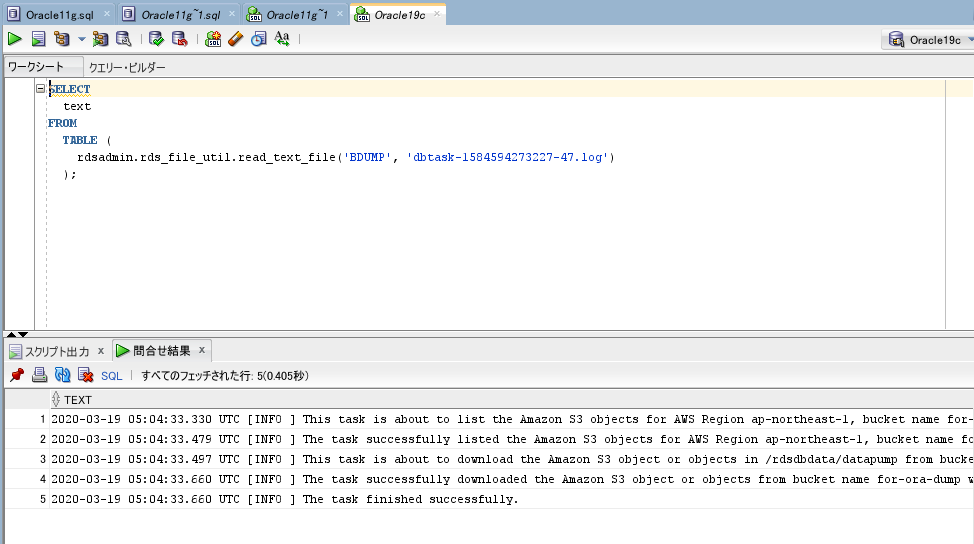
成功しています。
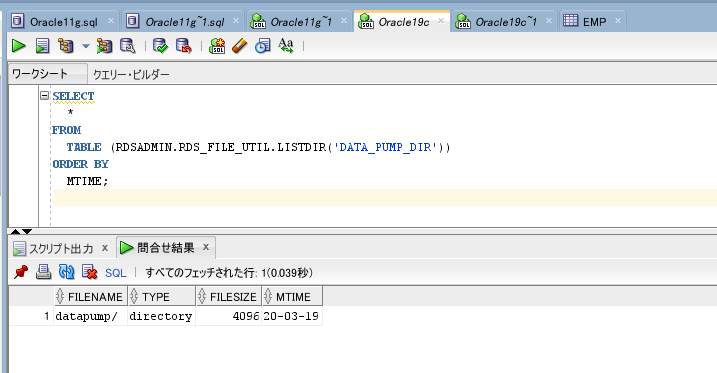
DATA_PUMP_DIRに存在する事も確認しておきます。
SELECT
*
FROM
TABLE (
rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')
);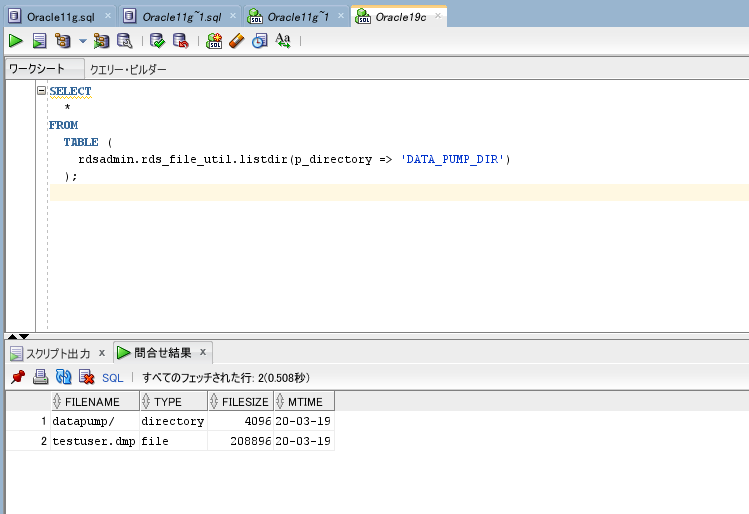
ありますね。
これで移行先DBへDumpファイルを持ってくる事が出来ました。
移行先へインポート
インポートを行う前に、表領域の作成を行います。
移行データが多い場合は、表領域を十分に確保しておくべきです。
AUTOEXTEND(自動拡張)オプションが有効になっていても、
データインポートに失敗する場合や、インポート自体にすごく時間がかかる事があります。
-- テーブルスペース作成
CREATE TABLESPACE ts1 DATAFILE SIZE 200M AUTOEXTEND ON MAXSIZE 1G;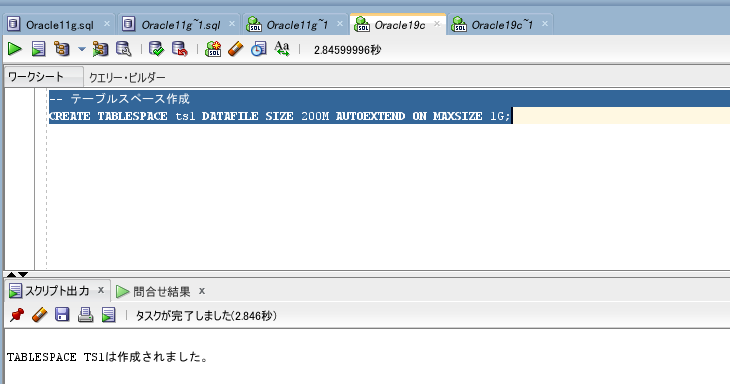
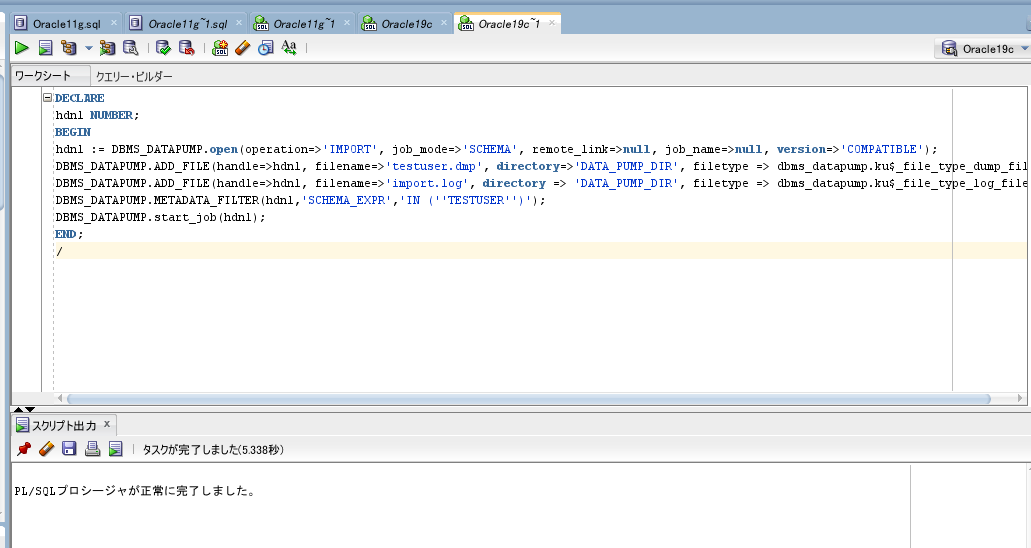
最後に、DBMS_DATAPUMPパッケージでインポートを行います。
以下のパラメータは適宜書き換えて下さい。
filename=>’Dumpファイル名’
filename=>’インポートログファイル名’
(hdnl,’SCHEMA_EXPR’,’IN (”スキーマ名”)’)
DECLARE
hdnl NUMBER;
BEGIN
hdnl := DBMS_DATAPUMP.open(operation=>'IMPORT', job_mode=>'SCHEMA', remote_link=>null, job_name=>null, version=>'COMPATIBLE');
DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'testuser.dmp', directory=>'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file);
DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'import.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file);
DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''TESTUSER'')');
DBMS_DATAPUMP.start_job(hdnl);
END;
/
インポート時のログ内容を確認してみます。
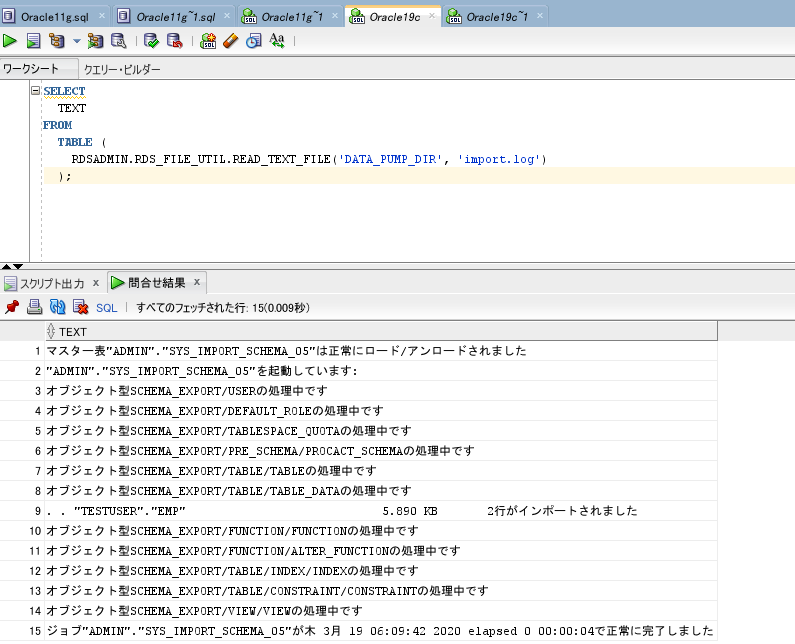
成功しています。
結果確認
移行先DBに再接続して、インポート後の状態を確認します。
テーブル、ビュー、ファンクションがそれぞれ作成されています。
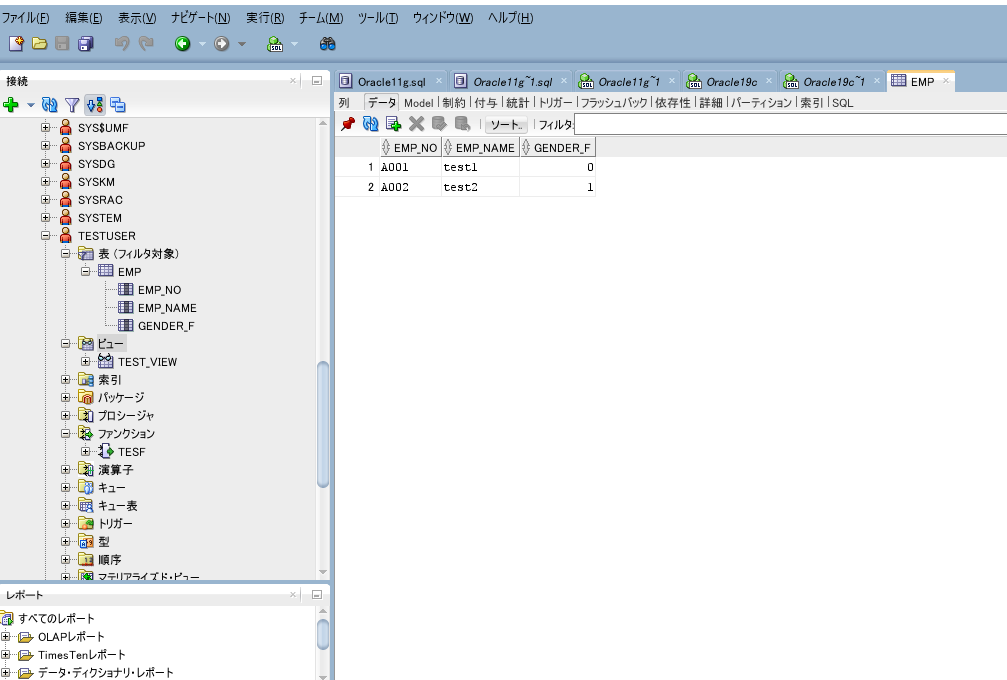
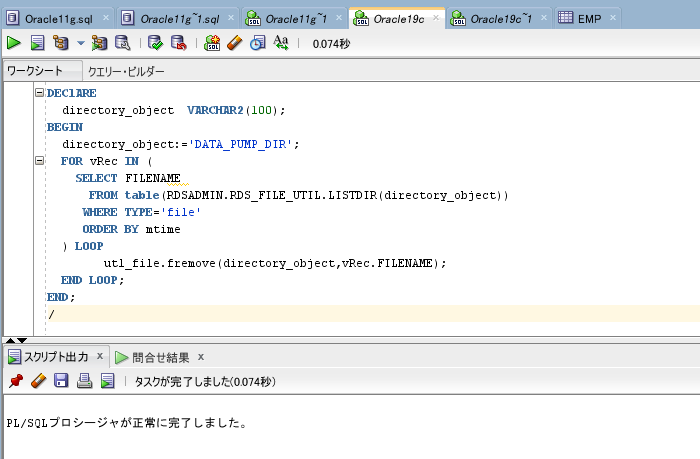
Dumpファイルのお掃除
今回使用したファイルのお掃除をします。
以下のPL/SQLを実行する事で、
DATA_PUMP_DIR内で作成したファイルを一括削除する事が出来ます。
必要に応じてご活用下さい。
DEClARE
directory_object VARCHAR2(100);
BEGIN
directory_object:='DATA_PUMP_DIR';
FOR vRec IN (
SELECT FILENAME
FROM table(RDSADMIN.RDS_FILE_UTIL.LISTDIR(directory_object))
WHERE TYPE='file'
ORDER BY mtime
) LOOP
utl_file.fremove(directory_object,vRec.FILENAME);
END LOOP;
END;
/
最後に
Oracle DBをRDS for Oracleへ移行する方法を、2通りご紹介させて頂きました。
次回は異なるDBエンジン間(OracleからPostgreSQL)でも、
AWSの純正ツール(SCT/DMS)を使用して、とても簡単に移行出来るので、
その方法をご紹介させて頂きます。
AWSで実践!OracleデータベースのDBマイグレーション 連載一覧
- Vol.25
- AWSで実践!DBマイグレーション時のRDS利用コスト削減
~ AWSのサービス 自動起動・停止を活用し使わない時間の料金を削減する ~ - Vol.24
- AWSで実践!異種間DBマイグレーション(Oracle to PostgreSQL編)
~ DMSでレコードを移行する ~ - Vol.23
- AWSで実践!異種間DBマイグレーション(Oracle to PostgreSQL編)
~ SCTでメタデータを移行する ~ - Vol.22
- AWSで実践!RDSへのDBマイグレーション(Oracle to Oracle編)
~ Data Pumpで移行する ~ - Vol.21
- AWSで実践!RDSへのDBマイグレーション(Oracle to Oracle編)
~ SQL Developerで移行する ~
↓↓ システムズのAWS DBマイグレーションに関する、Webページはこちらをご覧ください。 ↓↓